


In our previous blogpost, we outlined the problem with evaluating using pre-defined error taxonomies - these evaluations become stale (i.e. go off-policy) when your agent or domain shifts. This means you might miss the real issues hiding in your agent's traces!
For this reason, we believe that the best way to understand your agents' failures is to aggregate bottom up from your agents' actual (on-policy) traces. This is the process of error-analysis that Shreya Shankar and Hamel Husain refer to as one of the most critical techniques in evaluation.
Error analysis involves several steps, each of which are individually important, but can become laborious - meaning developers often gloss over or skip them, particularly in situations that necessitate shipping rapidly. We therefore found it of utmost priority to properly automate these steps [1], in order to enable scalable oversight and bring robust evaluation back into the limelight. Here we describe what worked for us (and what didn’t!) in automating each step:
TL;DR:
In pretty much every step, we can do a lot better than “stuff everything into an LLM judge prompt” with a bit of context engineering & old-school machine learning.
[1] As a small aside: though we are advocating for automating error analysis, similarly to Hamel and Shreya, we maintain the importance of inspecting traces. Hence, we have baked this into our tools, such that every automation doubles as a targeted mechanism to inspect traces - a necessary step to gain true understanding and ensure alignment of the evaluation system for your use case.
1. Open-coding: annotate traces for any anomalies
The first step in error analysis is to annotate your agents’ traces in an open-ended fashion (free of taxonomies), flagging any anomalous steps you notice. In other words, at every location in your trace that you encounter an erroneous step, write a natural language critique.
Annotation experiments
TL;DR:
✅ Step-by-step 'span-level' annotations using open-ended critiques show the highest human agreement & LLMJ alignment!
❌ All-at-once 'trace-level' annotations & fixed taxonomies show poor human agreement (noisy labels) and LLMJ alignment (missed failures)
Methods:
Span-level annotations:
We collected step-by-step span-level annotations on ~50 failed agent traces (~700 spans) of Tau-Bench, a popular agent benchmark from expert human annotators & prompted LLMJs. We compared two approaches:
- Human & LLMJs go through traces step-wise, labelling just the location of erroneous steps and writing open-ended natural language critiques
- Humans & LLMJs label both location and error-type of erroneous steps, using a fixed error taxonomy
Trace-level annotations:
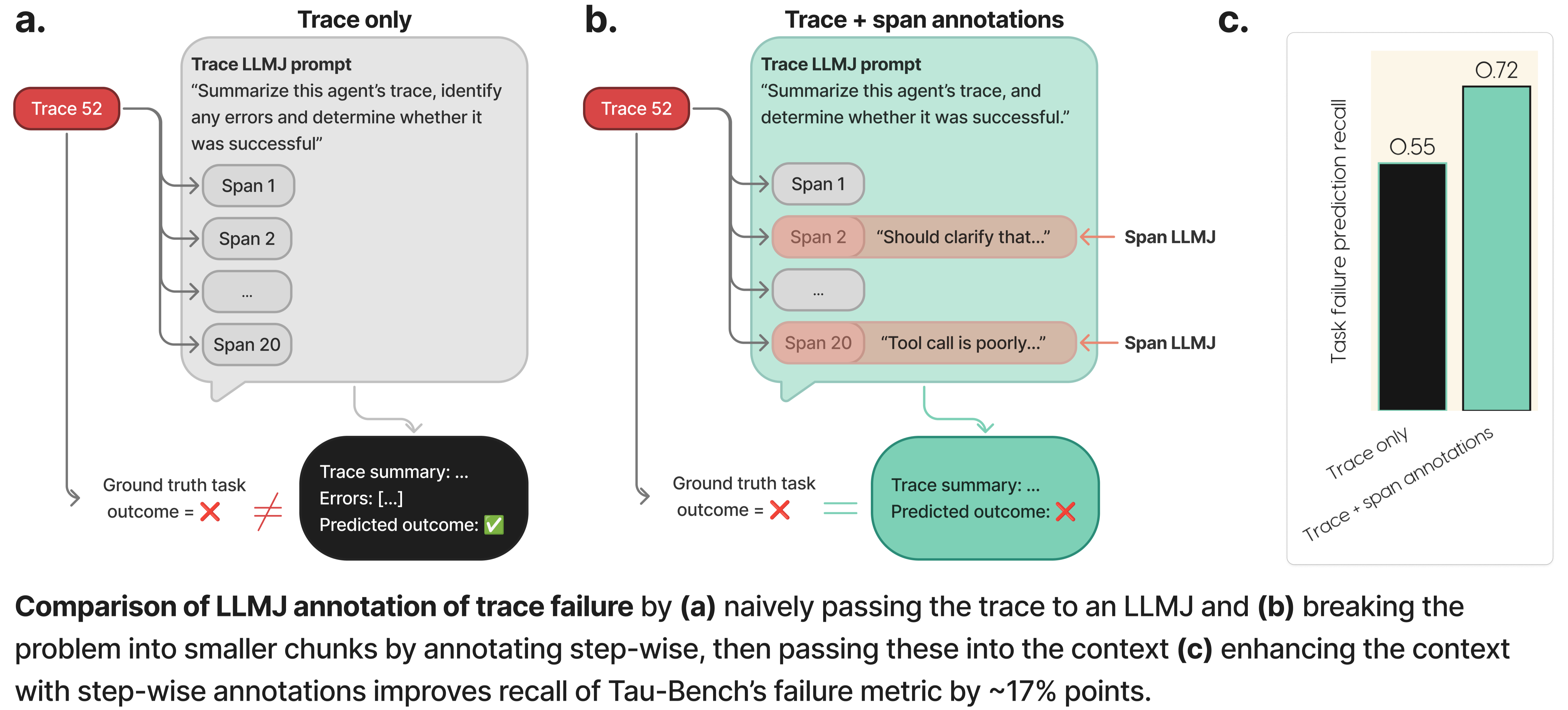
We performed trace-level annotations of every single trace (both successful and failed according to Tau-Bench’s criteria) using prompted LLMJs, comparing two approaches:
- Stuffing the entire trace into an LLMJ to predict a trace’s failure all at once
- Enhancing the context with step-by-step span annotations to predict a trace’s failure
We report inter-annotator agreement (IAA) using Krippendorff’s alpha unless otherwise mentioned, and judge alignment using true positive rate (TPR/recall) and percent agreement of human meta-judges, as applicable.
Results:
Span-level annotations:
- Humans have poor agreement on taxonomic error-type labels (IAA 0.094), but very strong agreement on error locations (IAA 0.865). Moreover, different annotators produce semantically similar critiques even when their labels differ - classifying these critiques into semantic labels yields high agreement (IAA 0.759) confirming to us that it's worth separating "critiquing" from "labelling" to get reliable signals to align on.
- We developed an agent-adaptive LLMJ to write open-ended critiques and flag error locations, aligned it to prioritise recall across agentic benchmarks [2], and had expert human annotators judge the judge on fresh traces (IAA on meta-judgements 0.782). Humans agreed with LLMJ flagged locations 88.5% of the time, and with the LLMJ’s critiques 64.3% of the time.
Trace-level annotations:
- Since Tau-Bench yields ground truth task success/failure, we can test our judges’ abilities to “catch” these task failures, by asking the judge to predict task failure and measuring TPR/recall of ground truth labels.
- We found that stuffing the trace into a naive LLMJ to predict failures all at once only catches about half the failures (recall 0.55), whereas enhancing the trace’s context with our step-by-step annotations significantly improves this prediction (recall 0.72).
We have since scaled up our agent-adaptive judge to generate span-level annotations and trace-level summaries across agents - and are iterating on it continuously using human feedback.
[2] Why optimise for recall? All subsequent steps (i.e. gathering human meta-judgements, clustering, etc) are capable of pruning false positives, but can only operate on flagged spans, hence we err on the side of over-flagging and then pruning.
2. Axial-coding: cluster patterns of failure
The second step in error analysis is to cluster your annotations from step 1 to aggregate them into common themes and patterns of failure - this becomes your (ephemeral) failure taxonomy.
Clustering experiments
TL;DR:
✅ Embedding-then-clustering annotations using non-parametric techniques produces specific and actionable patterns of failure.
❌ Naive clustering of annotations using a stuffed-prompt LLM produces vague patterns & does not scale.
Methods
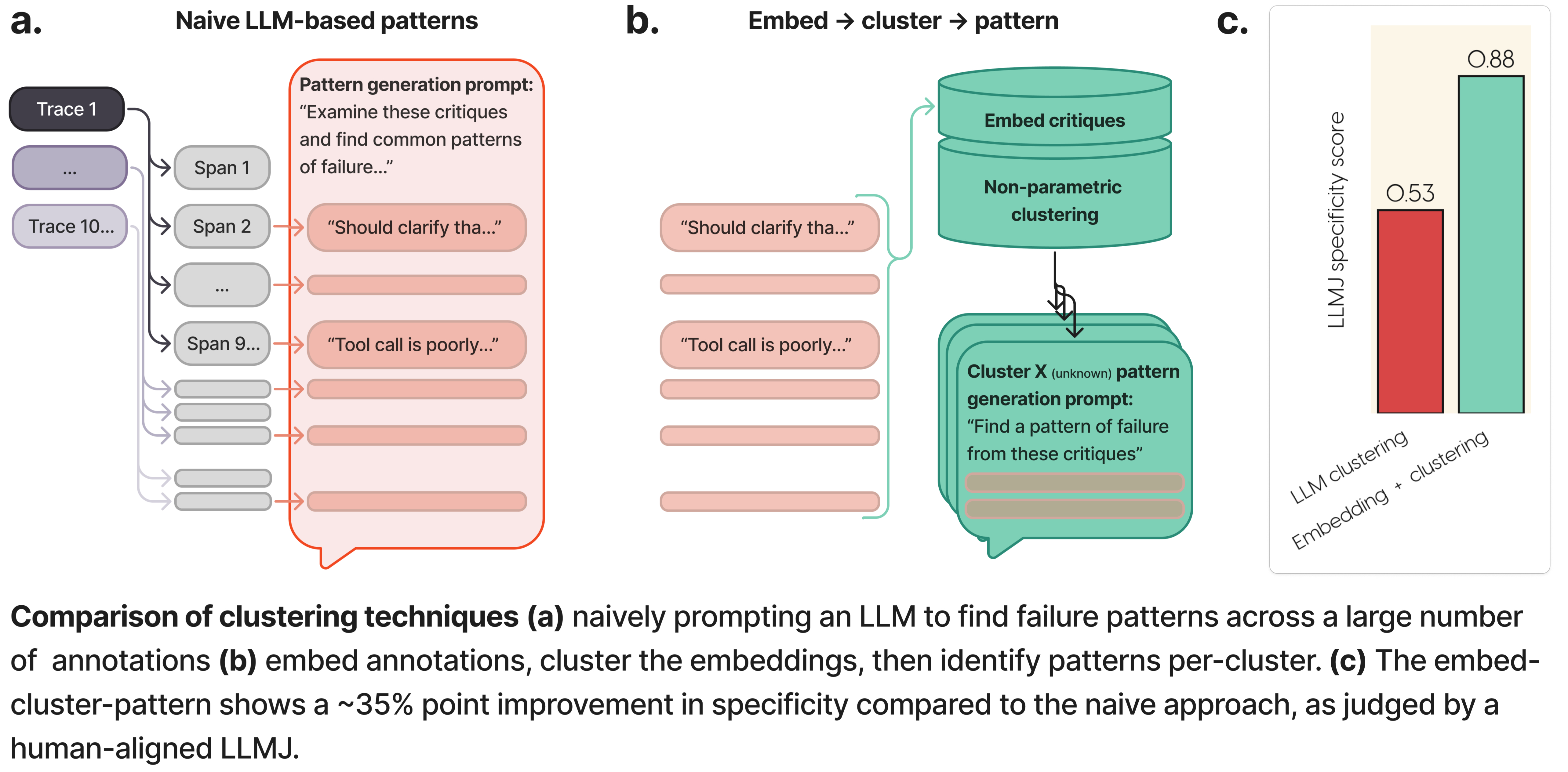
Now that we had annotations we trust - open-ended critiques on erroneous steps across traces - we compared two different ways of clustering these into (an unknown number of) custom, use-case specific failure modes:
- Naive LLM-based clustering of critiques, by stuffing a large number of critiques into the context window of an LLM, and prompting it to generate failure patterns
- Non-parametric clustering on embeddings of critiques, followed by generating a single failure pattern per discovered cluster.
Out of the box, these techniques have different trade-offs. Naive LLM-based clustering is methodologically simple, only requiring a single prompted LLM call, however, it is limited in scale by the context window, and can only be tuned through prompt engineering. Even when the context window can hold large amounts of information, practitioners increasingly find that “context engineering” can yield better performance.
Non-parametric clustering requires a fairly involved pipeline, but it can be scaled to millions of embeddings, and allows cluster discovery to be predictably tuned with hyper-parameters. It also decouples clustering from pattern generation, so we can selectively populate the context window of an LLM with a capped number of traces from a single cluster. We tuned each approach to generate a small number (5-10) of clusters across benchmarks & dataset sizes, then examined the generated pattern text.
Results
- While the naive LLM-based clustering approach yielded sensible groupings, generated patterns felt non-specific (example: red pattern around “inappropriate handoffs” doesn’t convey much). On the other hand, the embed-cluster-pattern approach yielded patterns that felt more tightly clustered (example: two green patterns, one failed handoff to a non-existent agent, and another failure to handoff to a support agent.)
- To quantify this, we had 3 human annotators agree on “specificity” criteria over 2 rounds of review, aligned a prompted LLMJ on a small dataset (recall 0.714) and used this to judge the two approaches at scale. We found that the embedding-based approach ranked significantly higher on specificity (87.5%) compared to the naive LLM-based approach (54.7%).

Re-coding for free!
One added benefit of the embed-cluster-pattern approach, is that the resultant clusterer state lets us automatically re-code new critiques into existing patterns online, in a way that is consistent with our original clustering. Notably, this gives us a system similar to defining an LLMJ/classifier to detect every single pattern for free, while maintaining separation from other patterns - no extra prompt-optimisation/alignment needed!
3. Iterative refinement: evolve your failure modes
The next steps in error analysis are essentially rinse-and-repeat - refine your failure modes until you can’t find any new ones. Once your failure modes are “snackable” as we like to say, you can track them over time & open PRs to fix them. Hurrah!
Not so fast though - now your agent’s policy has changed. You changed the prompt, you upgraded the model, your users are interacting differently with your agent, and new failure modes appear once again. How can you keep your failure modes fresh in the face of these complex, changing dynamics?
TL;DR:
❌ When agent policies change, reconciling taxonomies & re-clustering struggle with simultaneously satisfying stability (tracking recurring failures) and discovery (spotting emerging failures).
✅ Dynamic clustering offers a mathematically rigorous solution to satisfying stability and discovery requirements, allowing failure modes to evolve with your agent.
"You should frequently revisit this process." - Hamel H.
Without any automation, keeping your evals fresh requires the entire process of error analysis - open coding, axial coding, and re-coding - to be manually revisited 😅 In attempting to do so, we encountered two opposite challenges:
- The inertia of failure taxonomies: When investigating agent failures across benchmarks spanning vastly different use cases - first in Tau-Bench, then DA-code, then GAIA - previous versions of our failure taxonomy let us stably track familiar errors over time. However these also rendered the process of incorporating new kinds of errors laborious. Trying to preserve, split or merge old failure modes, while trying to properly fit new ones in took us several weeks, and is detailed in previous blog posts.
- The amnesia of re-clustering: We faced the opposite challenge in attempting to naively re-cluster new traces from scratch. While this allowed us to discover entire new sets of failure modes with each re-clustering, it rendered previous ones untraceable/irreconcilable.
Dynamic clustering
Fortunately, dynamic clustering techniques offers us a solution that builds on our automation of steps 1 and 2. One such solution is to enforce cluster correspondence between successive clusterings to maximise membership overlap.
The example below demonstrates two iterations of automated error analysis (critique → embed → cluster → pattern) on a coding agent’s traces, where an additional ~30% of traces have been added during the interval. One can see how the clusters, and hence failure modes, are evolving and being refined over time. Notably, cluster 4 is swallowed by cluster 2, while we have a new error emerging in cluster 5. It is visually clear to us how the clusters should link up, but defining this algorithmically is tricky.
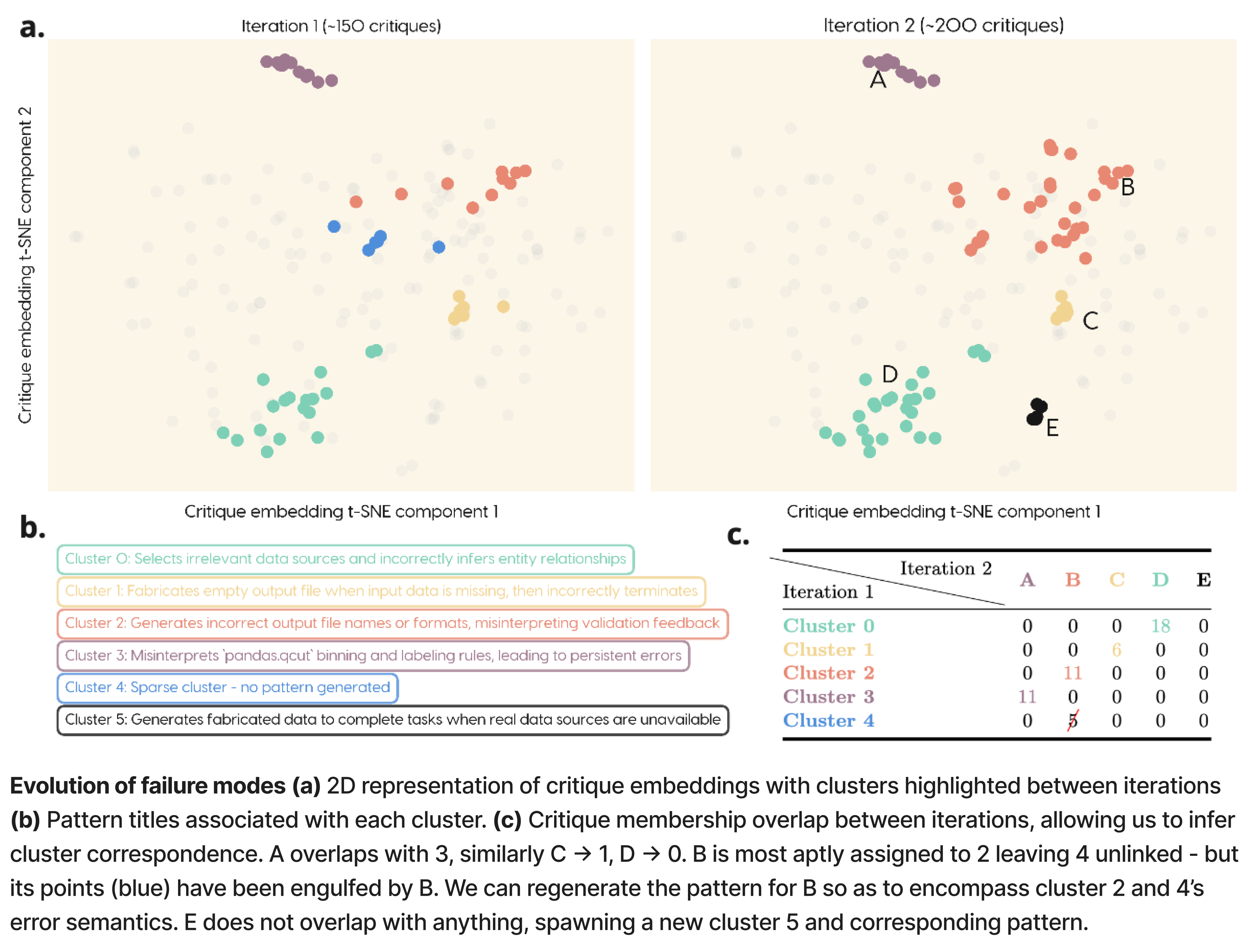
The Hungarian matching algorithm allows us to define the similarity of each cluster on iteration N to each cluster on iteration N+1 by membership overlap. The algorithm is guaranteed to find the optimal cluster correspondence in polynomial time, permitting the smooth evolution of clusters in the figure above, and hence failure patterns between successive iterations of clustering.
How fast to iterate?
Our system now gives us access to three cadences of automation:
- New traces are automatically open-coded, and can be automatically assigned to failure patterns online. Notably, this gives you a system similar to defining your own LLMJ to detect specific failure modes for free - no prompt-optimisation of judges required!
- Clustering can be revisited every X days (or more/less regularly) to refine cluster boundaries as more instances of the same errors arise, to detect new error clusters, or to unlink outdated ones as they become less prevalent.
- Failure patterns can be regenerated every Y days (or more/less regularly) to refine the semantics of a given cluster as its membership changes over time.
Combined, these automate the iterative refinement step of error analysis, yielding stable, yet evolving failure modes. Some challenges remain, in particular, intelligent choices of the cadences of clustering and pattern generation depend on the user’s development workflow and how far the current policy has diverged from the previous policy.
Discussion
And there you have it - through our experiments, we’ve found that a little bit of context engineering and machine learning goes a long way in enabling scalable oversight, by automating the 3 stages of the process of error analysis described by Hamel and Shreya.
Importantly, each of these automations leave room for humans-in-the-loop to guide the process, while also guiding the human to relevant traces like a searchlight. Rather than exhaustively skimming through traces, our humans are directed towards potentially erroneous traces within a failure pattern that they can inspect/like/dismiss, and further towards potentially erroneous steps within a trace that they can inspect/like/dismiss.
We have been using this framework internally at Atla to monitor and improve agentic systems, and are excited to build the next generation of evaluations systems that continuously adapt to human feedback.





