


TL;DR:
- Voice agents are rapidly growing in popularity.
- They pose more challenges than text-based agents, requiring more complex infrastructure, benchmarks, and evaluation.
- And yet, evaluation tools are still in their infancy: they fail to capture system-level behavior and offer little insight into how the audio modality shapes performance.
- Atla has extended its applied research to enable use of its automated error analysis suite on audio-native metrics and voice agents.
When your voice agent speaks, it speaks for you. Are you making sure it’s representing you in the right way?
With the rise of agentic AI, there’s been a particularly strong interest in the voice modality. Some reasons for this include the convenience of interacting conversationally, gains in model capability and efficiency that enable their practical use, and clear business use cases such as customer service and healthcare triage where voice agents naturally augment human operators.
But as voice agents handle more real-world conversations, the same qualities that make them engaging–natural speech and spontaneity–also make them more prone to a variety of errors that the field of AI evaluations hasn’t quite caught up with yet.
Freedom of speech: The challenges evaluating voice agents
Voice agents exhibit every potential failure mode as textual LLM agents, and more. Added complexity includes:
- Handling noisy waveform data, e.g. from background noise.
- Parsing the audio content as natural language.
- Overlapping conversational turns as humans and agents interrupt and speak over each other.
- Understanding paralinguistics, such as emotive inflections, volume, and tone.
Further, while vocalising is generally quicker than typing, reading (230-300 wpm) is typically faster than listening (150-160 wpm). Thus, it’s more time-consuming to listen back to and understand an agentic voice trajectory than a textual trajectory.
These complications naturally spawn the need for new forms of evaluation and scalable oversight.
Giving agents a voice: How they work under the hood
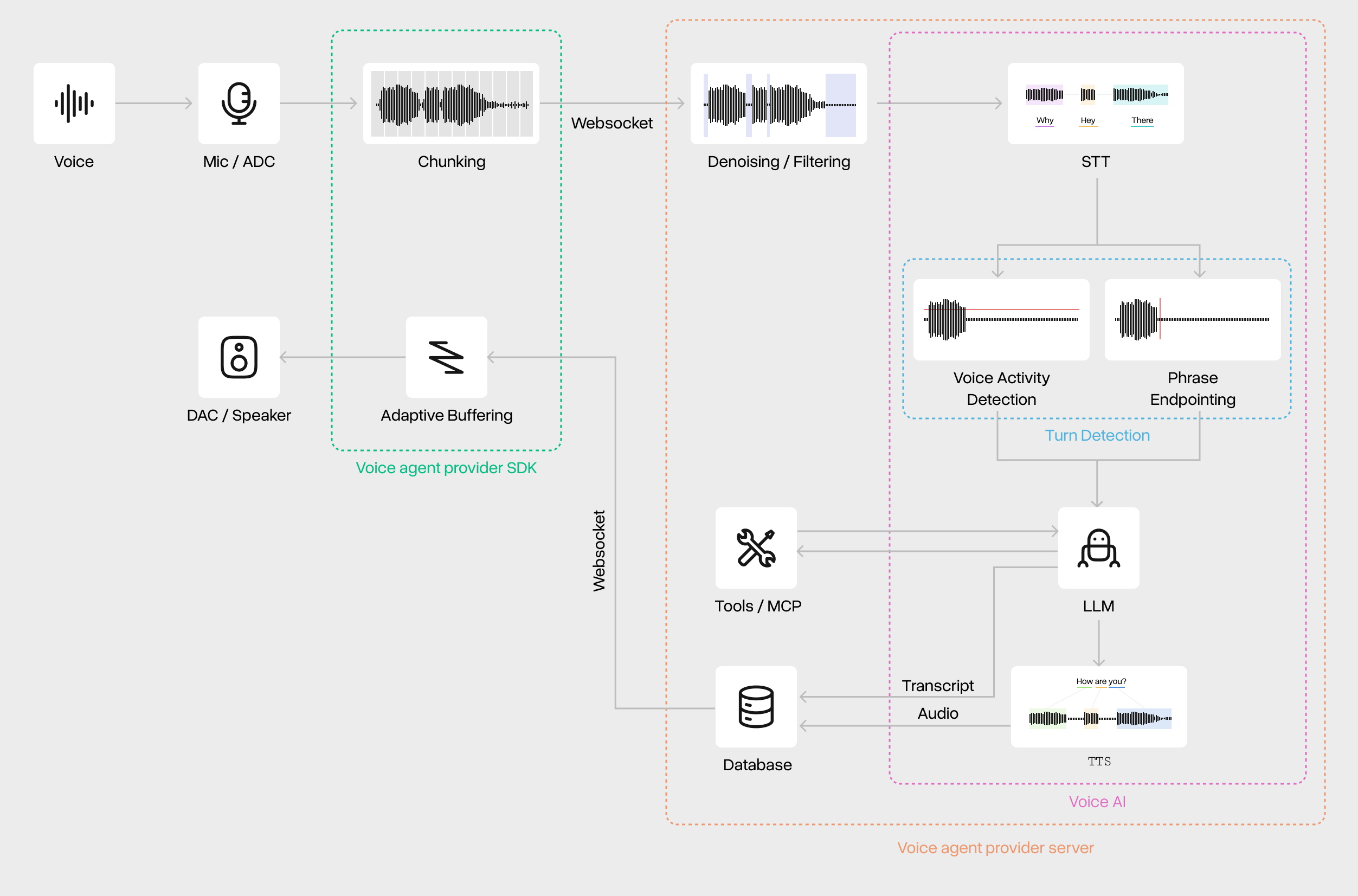
However, the voice agent adds some additional logic that is worth grasping. As one speaks, the audio recording bytes are chunked and streamed via websocket to the model provider. After some denoising steps, Speech to Text (STT) converts audio information into textual language that is more easily processable by a Voice Activity Detection (VAD) component. This flags when a user is speaking to terminate the voice agent’s output and not interrupt the user. Another important component is Phrase Endpointing, that determines when a user has ended their turn, and would likely need a response from the AI. Simple versions can mean acknowledgements or phrases such as “hmmm” trigger interruptions, thus, more recent Turn Detection algorithms extend the functionality.
At this point, the LLM will receive a transcript that it uses to perform the usual text-based agentic activities. Though, there is often a greater focus on asynchronous tool calls, that allow the voice agent to talk to the user while waiting for a potentially time-consuming request to come back, mitigating awkward silences. Output tokens are converted back to audio via Text to Speech (TTS) for auditory consumption. Usually, an Adaptive Buffering component is used to, firstly ensure that time-to-first-token is as short as possible, and secondly to ensure that drops in network speed or token output do not cause choppy audio.
This framework more accurately represents what is going on under the hood in systems like ElevenLabs’s and Sierra’s voice agents. OpenAI, on the other hand, with its end-to-end audio model, won’t consist of separate STT and TTS steps, and may even leave turn detection entirely up to the model itself for ultimate bitter-lesson-pilling.
Finding the right frequency: The voice agent evaluation landscape
Benchmarks
Naturally, one may jump to benchmarks to evaluate an agent. Popular text-based agent ones include SWE-bench, GAIA, and 𝛕-bench, but audio-native benchmarks are sparse and haven’t taken off in the same way. A few examples include:
- MMAU: Multifaceted audio-understanding and reasoning but only on text output content.
- VoiceAssistant-Eval: Acoustic evaluations but outside of the agentic setting.
- VoiceAgentBench: Evaluating speech LMs in agentic settings but without focus on paralinguistic variations.
Reasons for this sparsity include the time and expense of synthesising vocal conversations, though we expect this to improve over the coming months.
In addition, as Atla’s Sashank Pisupati described in one of our recent blogs, public benchmarks don’t reflect the conditions your agent will face in your actual production environment - i.e. they are “off-policy”. Due to this mismatch, you need an “on-policy” method that evaluates the agent within the real context in which it’s deployed.
Beyond static benchmarks
The text-based agent evaluation landscape is more mature, in which developers are coalescing on some evaluation steps and workflows to enable fast (policy) iteration. These include using LLMs-as-a-Judge (LLMJs) to grade responses on specific evaluation criteria, creating evaluation datasets as offline test cases, refining evaluation prompts, or Atla’s own solution of automating online error analysis, that is the most fundamental (in my biased, but also Shreya Shankar’s unbiased, opinion).
For voice agents, many of these assumptions hold and should still apply as general frameworks, but here we will focus on points that are specific to evaluating audio content and would not arise in text-based agents.
To be more concrete, aspects of the system that have been introduced are audio input parsing, turn detection, and audio output quality. We can break down metrics that try to make sense of these into two types:
- Algorithmic metrics: Use a deterministic algorithm applied to the audio data. This alone does not provide the necessary actionable insights about where/why an agent deviated from its ruleset to perform error analysis. Aggregation would be required to obtain some overarching information about a system’s health.
- LLMJ metrics: Use an AI judge to grade on arbitrary criteria specified by natural language. This can indicate issues with the underlying AI’s instructions or code that should be corrected.
Table 1 introduces some specific examples of audio-native metrics that can be calculated. It should be noted that a holistic evaluation would not only grade on these criteria individually. Atla’s approach allows for a more open-ended analysis that ties together how misalignments of the agentic system are specifically affected by the audio modality, explainably grounded in these measures.
.png)
The majority of tooling focuses on the algorithmic metrics, while very little focuses on truly audio-native LLMJ metrics. There is, therefore, a gaping hole in the AI safety field. There currently does not exist adequate tooling to scalably and effectively evaluate voice agents’ traces, which will become evermore pertinent as the market grows.
The sound of alignment
Atla is working to plug this hole. Building atop our foundation of training frontier (text) LLMJ models and developing agentic evaluation and alignment tools, we have extended our applied research to handle audio-native signals. This will augment our automated error analysis approach that could turbocharge your agent development too:
- Open-coding - annotate traces for any anomalies,
- Axial-coding - cluster patterns of failure,
- Iterative refinement - evolve your failure patterns online.
We are building evaluations that can listen, understand, and judge a voice agentic system end-to-end on its semantic and paralinguistic failure patterns. This shift enables scalable oversight across modalities, bringing unified observability to text, audio, and eventually multimodal agents alike. Voice agents don’t just speak - they perform. And evaluating this performance means hearing, not just reading. As we move toward this new frontier, we’re excited to collaborate with teams exploring the same question: how do we keep agents aligned when they start to sound like us?
Thanks to Max Rollwage @ Limbic AI for his feedback.





