


The increasing complexity of agentic tasks necessitates automated approaches to evaluation [1].
However there’s one aspect of automated trace evaluation that we have always found unsatisfying: the flattening of complex traces into a single block of text. This is convenient for the purpose of stuffing the trace into an LLM for evaluation, but it loses much of the tree-like structure of the original trace.
At Atla, we have found that preserving the tree structure of traces has many advantages. Not only does it make for more token-efficient trace ingestion, it also unlocks smarter evaluation techniques such as forward and backward traversal, allowing us to improve both recall and precision of finding errors.
[1] https://www.atla-ai.com/post/automating-error-analysis
Traces are trees
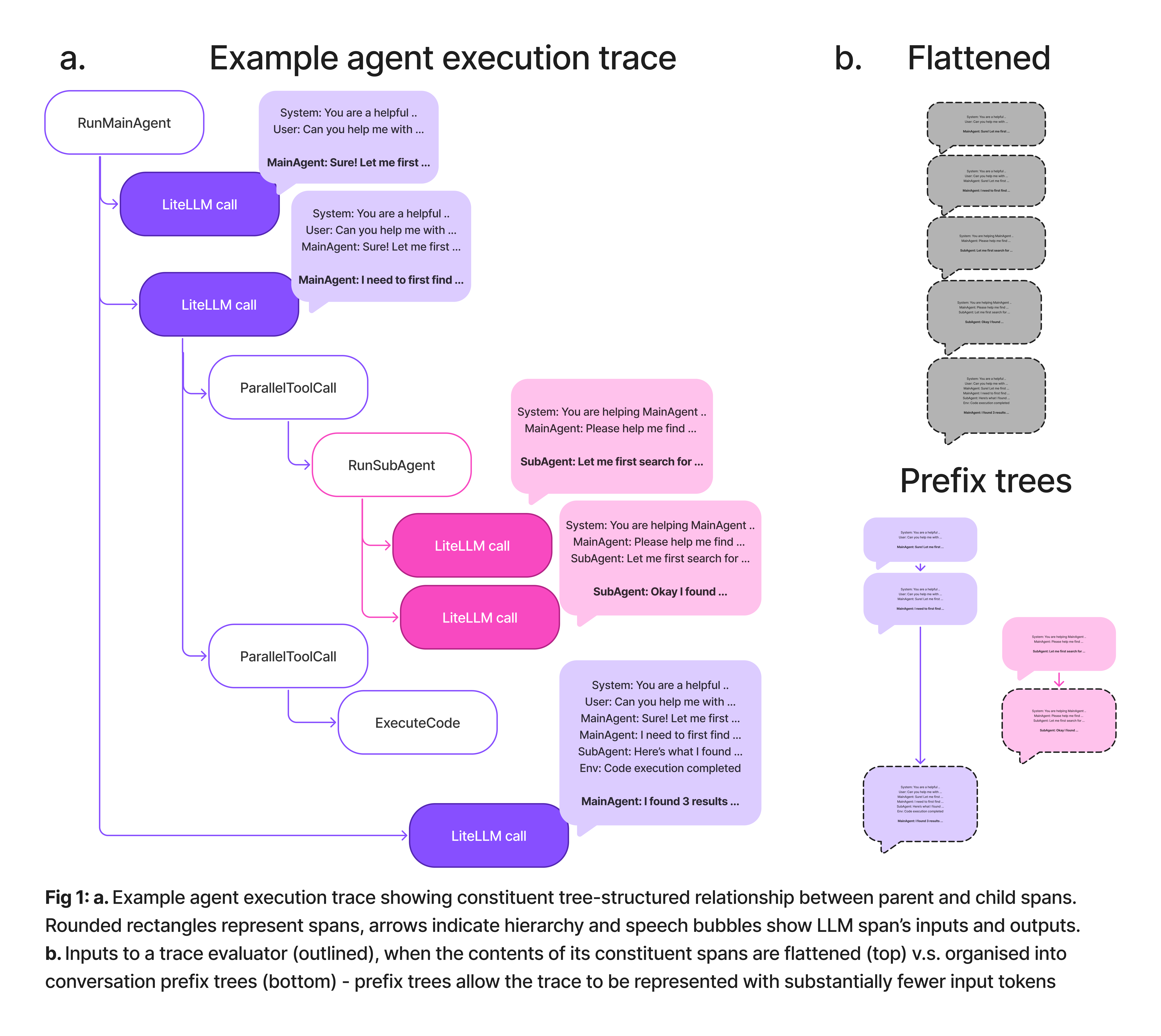
To understand how traces are trees, let us first understand how agent execution traces are typically represented by observability tools, using standards such as OpenTelemetry.
At its core, agent execution can be understood as a sequence of LLM calls interspersed with code execution, tool calls, user/environment interactions etc. When you instrument this with an observability tool, each of these operations is captured as a span: a structured record of what happened, when it started and finished, and important metadata such as inputs and outputs.
Spans are linked together in a parent-child hierarchy to form a trace, which is not just a linear chain, but a tree: a single LLM call span can trigger several child spans in parallel (e.g. 4 tool calls at once), or hand off to another agent whose work becomes a new branch.
Conversations are prefix trees
One of the first things you’ll notice in the example, is that the conversation between a user and a single LLM agent doesn’t look like a simple, growing list of messages. Instead, it looks like a growing prefix tree across the inputs of several successive LLM spans! Each successive span appends to the inputs the previous LLM output, and any user/environmental inputs that occurred in between LLM calls. Changing system prompts breaks the prefix tree, such as multiple agents with their own system prompts and hence their own entirely separate prefix trees [2].
Smartly ingesting this structure lets us represent the trace much more compactly, as a collection of conversation prefix trees, related to each other through span parent-child relationships. For example, in the trace above there are 5 LLM spans that we could evaluate, each with its own conversation history - but only 2 growing prefix trees, one for each agent! This compact representation is much more token efficient, and lets us take advantage of prefix caching in the evaluator LLM, in a way that stuffing the flattened trace with each span’s inputs would not.
[2] Note: depending on your agent framework/implementation, you may not even get a single clean prefix tree for a single agent, especially if your system prompts or function definitions change mid-execution. For instance, Matt Henderson at PolyAI has astutely pointed out that changing functions breaks prefix caching in OpenAI’s function-calling APIs since function definitions are placed at the start of the prompt.
When you see a tree, traverse it
The second feature invoked by paying attention to the tree structure of the trace, is the notion of traversal. Rather than consuming the entire tree all at once, we can traverse the tree, pausing at every LLM span and evaluating the conversation up to that point. We can even generate some output tokens at this point, leaving ourselves “notes” about anything that has gone wrong so far, before continuing with our traversal. Then, once we’ve consumed the entire tree, we can evaluate it taking into account the notes we have left ourselves.
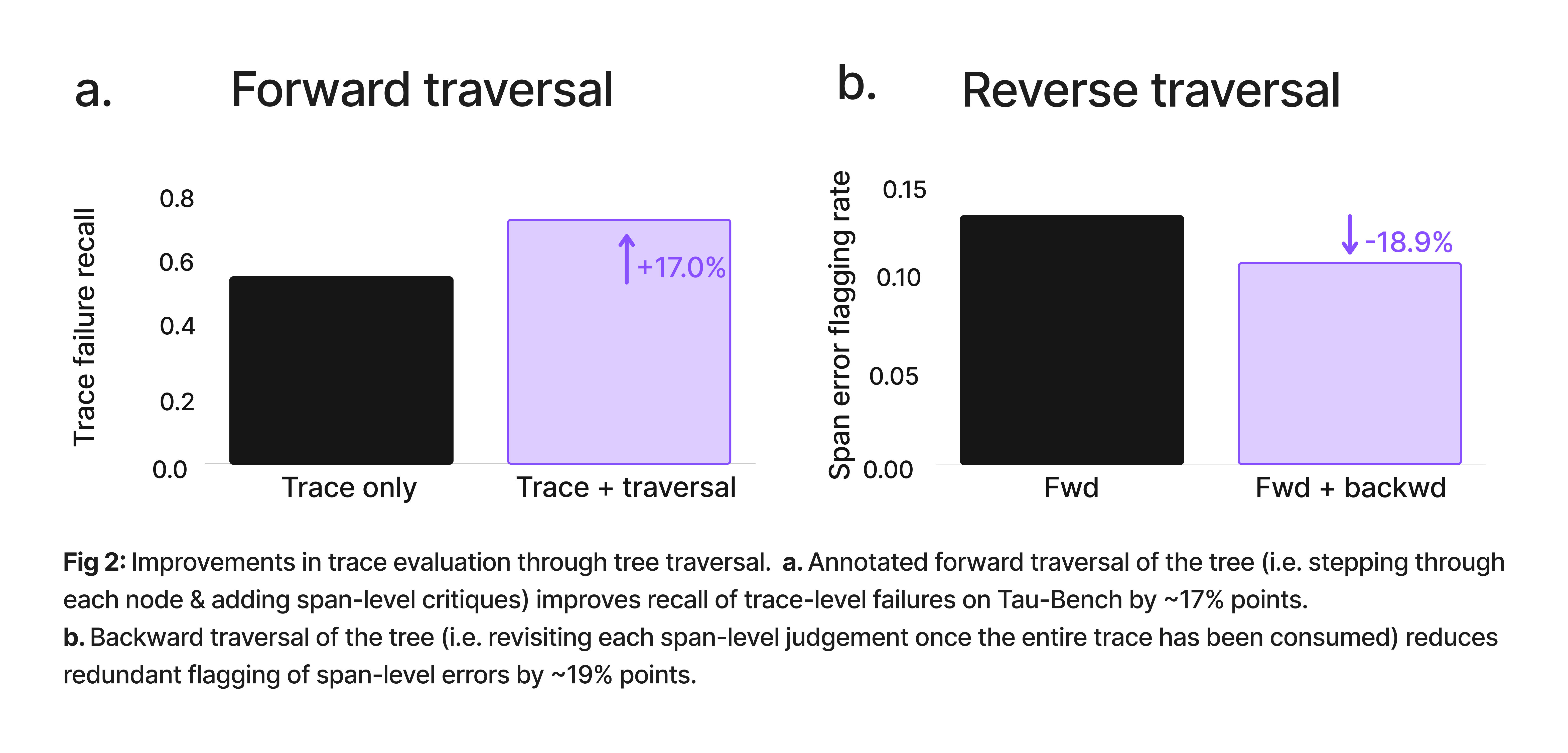
We compared this “traversal” style evaluation, with added notes at each node, with a vanilla evaluation that simply consumes the entire trace at once. In both cases we attempted to predict whether the trace was a failure or not on traces from the Tau Bench benchmark (where we have ground truth labels of trace failure). We found that annotated traversal boosts recall of trace failure by ~17% points [1], even when using the exact same long context LLM to predict failure.
Put it down, flip it and reverse it
Another mechanic unlocked by tree structures is the ability to traverse the trace in both forward and backward directions! Most step-level evaluations proceed in “forward” mode i.e. they step through successive LLM spans, evaluating each span only given knowledge of previous spans. However, sometimes deciding if a given step is mistaken requires knowledge of how future steps proceed. We actually have this knowledge when evaluating entire traces, and risk discarding it when we evaluate step-by-step in the forward direction. On the other hand, when we don’t evaluate step by step, we risk either overlooking small details (see the lower recall in Fig 1), or unfairly judging LLMs based on information they could not have possibly had during generation.
Luckily, traversal gives us an elegant solution that yields the best of both worlds; we can first traverse the trace “forward”, fairly judging each generation only using the context available to it, and once we reach the end of the trace, run a “backward” evaluation that prunes our judgements using the benefit of hindsight. This lets us distinguish mis-steps that ended up being consequential for task failure (we call these root-cause errors) from those that had no cascading effects, or have been flagged redundantly multiple times. This turns out to be a great way to prune false positives and improve precision without sacrificing recall.Across 7 different agent datasets, we noticed an average reduction of ~19% in redundant flagging of step-level errors using this technique.
At Atla, we have incorporated all three of these techniques into our automated agent evaluation pipeline, to ensure that our failure patterns are specific and actionable. To see them in action, try our demo.





